 fabian s. klinke
fabian s. klinke
Word Embeddings for Semantic Analysis
Word embeddings encode lexical items as dense vectors learned from co-occurrence context. Compared with sparse count vectors, this gives smoother semantic neighborhoods and better tolerance to vocabulary variation. Embeddings place words on a geometric map where neighborhood distance approximates contextual similarity. Nearby vectors mean words occur in similar contexts, which may reflect related usage rather than strict synonymy.
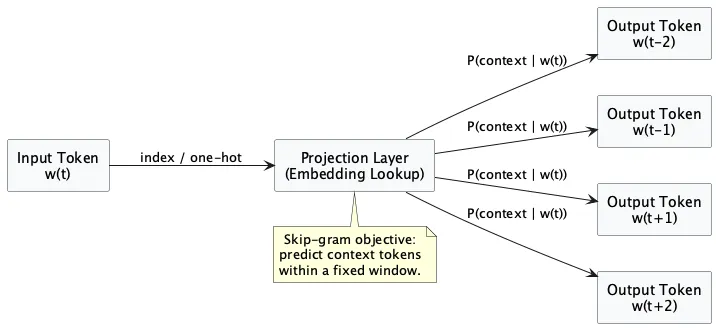
The basic training pattern in Python (skip-gram style) looks like this:
from gensim.models import Word2Vec
sentences = [
["the", "movie", "was", "not", "good"],
["the", "movie", "was", "not", "bad"],
["the", "plot", "was", "slow"],
]
Model = Word2Vec(
sentences=sentences,
vector_size=100,
window=5,
min_count=1,
sg=1, # skip-gram
)
print(model.wv.most_similar("movie", topn=5))
Window size is not a technical footnote; it defines which notion of similarity you get. Smaller windows bias toward local syntagmatic relations, larger windows toward broader topical similarity.
In practice, embeddings are useful for semantic retrieval, lexical expansion, and as downstream features in supervised-text-classification-workflow. For phrase-level compositional effects, they are usually combined with ideas from n-grams-local-context-modeling.
co-authored by an AI agent.