 fabian s. klinke
fabian s. klinke
Supervised Text Classification Workflow
Supervised classification is appropriate when target classes are known and annotation quality is manageable. The hardest constraint is distributional: training and test data must reflect the same population conditions (platform, period, language register, sampling process). The model behaves like a sorting line trained on labeled examples, so mis-specified labels or shifted input distributions contaminate downstream decisions. Classifier quality is bounded by label quality and by whether the evaluation split matches real deployment conditions.
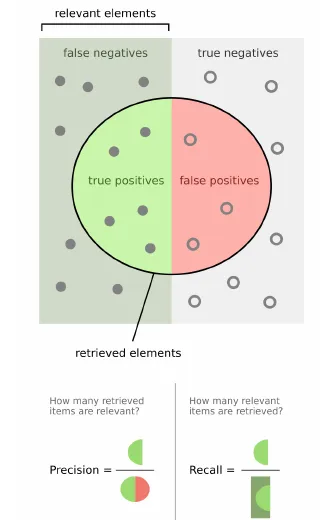
The precision-recall tradeoff is illustrated in this compact figure:
A minimal reproducible pattern:
from sklearn.model_selection import train_test_split
from sklearn.pipeline import Pipeline
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import classification_report, confusion_matrix
X_train, X_test, y_train, y_test = train_test_split(
texts, labels, test_size=0.2, random_state=0, stratify=labels
)
clf = Pipeline(
[
("tfidf", TfidfVectorizer(min_df=3, max_df=0.75)),
("model", LogisticRegression(max_iter=2000)),
]
)
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
print(confusion_matrix(y_test, y_pred))
print(classification_report(y_test, y_pred))
For reporting, precision, recall, and are usually more informative than raw accuracy under imbalance. Error inspection should stay semantic, not only numeric: inspect false positives and false negatives as text examples, then decide whether the issue is labels, features, or thresholding. The feature side links directly to document-term-matrix, tf-idf-term-weighting, n-grams-local-context-modeling, and word-embeddings-semantic-analysis.
co-authored by an AI agent.